
GOV.UK Notify lets central government, local authorities and the NHS send emails, text messages and letters to their users.
We usually send between 100,000 and 200,000 text messages a day. It’s important for services using Notify that they’re able to quickly and successfully send text messages to their users.
Those services rely on us to send important messages, for example a flood warning or a two-factor authentication (2FA) code so their users can sign in to another service. We design and build Notify with this in mind.
Using multiple text message providers
When a central government, local authority or NHS service wants to send a text message to a user, they ask Notify, either manually through our web interface or using our API, to send it. We then send an HTTP request to a text message provider to ask them to deliver the message. No provider will be working perfectly 100% of the time (nor should we expect them to be). Because of this we have 2 different providers, so if one encounters any issues we can use the other provider to send the message.
Our original load balancing design
Originally we sent all text messages through one provider, say provider A. If provider A started having trouble, Notify would automatically swap all traffic to provider B – a process known as a failover. We used 2 measures to decide if a provider was having problems and failover. We measured a:
- single 500-599 HTTP response code from the provider
- slowdown in successful delivery callbacks (a message back from the provider to say it had delivered the message to the recipient)
To determine if callbacks were slow, we’d measure the last 10 minutes of messages being sent. We’d consider callbacks slow if 30% of them took longer than 4 minutes to report back as delivered.
We could also manually swap traffic from, say, provider A to provider B as we wanted. We did this often, maybe once a week, to try and reach a roughly 50/50 split of messages sent between each of our providers. If we ended up sending only a small number of messages through one provider over the long run, they might not be massively incentivised to be a provider in the future.
A problem with our original design
One day, towards the end of 2019, we had a large spike in requests to send text messages. We sent all these requests to one of our providers but it turned out they couldn’t handle the load and started to fail. Our system swapped to the other provider but it turned out that sending a large amount of traffic out of nowhere caused them to start returning errors too. It was likely that our providers needed time to scale up to handle the sudden load we were sending them.
How we improved our resiliency
We changed Notify to send traffic to both providers with a roughly 50/50 split. When a single text message is sent, Notify will pick a provider at random. This should reduce the chance of giving our providers a very large amount of unexpected traffic that they will not be able to handle.
We also changed how we handled errors from our providers. If a provider gives us a 500-599 HTTP response code, we would reduce their share of the load by 10 percentage points (and therefore increase the other provider by 10 percentage points). We will not reduce the share if it’s already been reduced in the last minute.
We also decided that if a provider is slow to deliver messages, measured in the same way as before, we would reduce their share of the load by 10 percentage points. Again, we will not reduce the share if it’s already been reduced in the last minute.
It’s important that we wait a minute before allowing another 500-599 HTTP response code to decrease that provider’s share of traffic again. This means that just a small blip, for example five 500-599 HTTP responses over a second, doesn’t switch all traffic to the other provider too quickly.
Equally balancing our traffic
We still had the manual task of equally balancing our traffic if we no longer needed to push that traffic towards one of the providers. We decided that, if neither provider had changed its balance of traffic in the last hour, we’d move both providers 10 percentage points closer to their defined resting points.
This means our system will automatically restore itself to the middle and removes the manual burden of our team trying to send roughly equal traffic to both providers. We can still manually decide what percentage of traffic goes to each provider if we want to, but this is something we anticipate doing rarely.
We did consider trying to overcorrect traffic to bring the overall balance back to 50/50 over, say, a month. For example, if provider A has an incident and receives no traffic for 24 hours, we could give it 70% of the traffic for the next few days to overcorrect the traffic it lost. We decided doing this would only bring a small benefit and would increase the complexity of our load balancing system. Keeping things as simple as possible won the argument in this case.
How the service is doing now
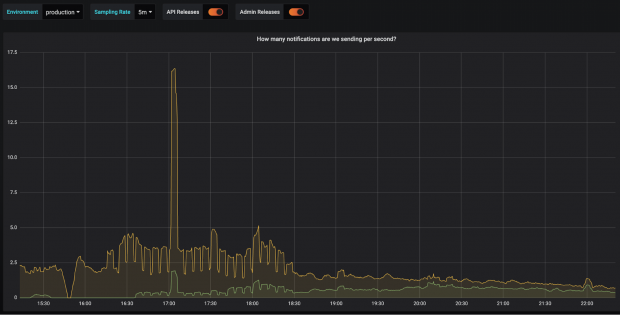
The following graphs show the number of text messages we sent to each of our providers per second.
On the morning of 26 January one of our providers ran into problems and we reduced their share of traffic down to zero. Every hour for a while after this you can see us give them 10% of traffic to see if they have recovered enough, but they hadn’t so it got reduced back to 0% again.
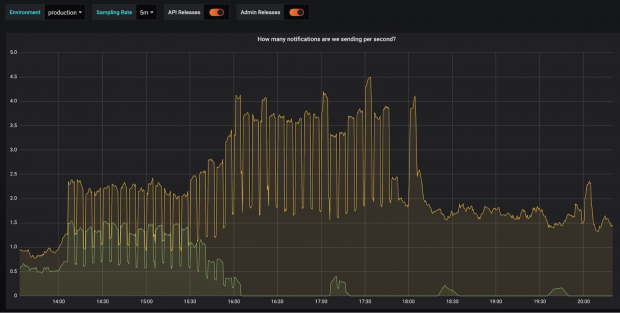
Finally the next afternoon their system improved and we moved back towards a roughly equal split of traffic.
What’s next
This fix works for us now. As we continue to grow we'll do more stuff like this to make sure we're providing the best performance, resilience and value for money to Notify’s users.
Visit GOV.UK Notify for more information and to create yourself an account.


22 comments
Comment by John Labon posted on
Hi i am in the vulnerable group and was receiving texts about staying at home and for how long ect as i have COPD but have not receved anything since 29th march why is this thanks.
Comment by The GDS Team posted on
Hi John,
Please reregister yourself as a clinically extremely vulnerable person and say no when asked if you have a way of getting essentials.
Thanks,
The GDS Team
Comment by John posted on
Thank you for your help ?
Comment by Lindsey posted on
Hi
Is this text from GOVUK fake:
You have been identified as someone who may be at high risk of severe illness if you catch Coronavirus. You may have been contacted previously and asked to register for support in getting food and basic care.
We would like to confirm we have the correct details for you.
If you still require support in getting food and care please complete the short form again at https://www.gov.uk/coronavirus-extremely-vulnerable.
Before you start, make sure to have your NHS number to hand which you will find on any letter the NHS has sent to you or on a prescription.
If you cannot sign up on the website, call us on 0800 028 8327
Thanks
Lindsey
Comment by The GDS Team posted on
Hi Lindsey,
If you are concerned that you did not register as extremely vulnerable, please do so. If your registration is successful you will reach a page that tells you so and receive a confirmation email or text message. If you think you were erroneously registered, you can contact your local council to remove you from their list. You can find your local council if you don't know it.
Thanks,
The GDS Team
Comment by John posted on
Hi Lindsey that text is genuine its the same as the one i had its for people who are in high risk groups ( vunerable )because of health issues
Comment by Lindsey posted on
Thanks John. It’s very confusing as I have had a text from UK_GOV and GOVUK and wondered if one was a phishing attempt.
Comment by Janis Howells posted on
Is a text headed GOVUK genuine? I think it might be a scam
Comment by The GDS Team posted on
Hi Janis,
The government has sent a text message to people across the UK. If you have been sent a suspicious text message you can forward this to 7726.
Thanks,
The GDS Team
Comment by Michael John posted on
It seems "extremely vulnerable" is interpreted as being a cancer patient only, so I couldn't register in Mum's name. I shall try the county council now.
Vulnerable people are also people dependent on life saving medication.
Comment by The GDS Team posted on
Hi Michael,
The criteria for extremely vulnerable people is published. Her GP may also be able to assist in this matter.
Thanks,
The GDS Team
Comment by Michael John posted on
Thank you. I've written to Tendring Council.
Comment by Michael John posted on
Dear GDS team :
It would be much better, if people like her, extremely proud and not wanting to be a burden to society, could be registered by relatives. By me for example. Even if they live in a different country. Is this possible? Luckily she still has her faculties together and is now trying to order food online because she dares not go out. Help is just far too slow. I dread to think what is happening to other elderly people, who can't operate a computer. Please be aware of these circumstances. When the government says "stay at home", they should unterstand and prepare for the consequences When can and will somebody do something about this? I am deeply concerned and rely on a good neighbour to see how she is.
Comment by The GDS Team posted on
Hi Michael,
You can register someone on their behalf. You can also contact her local council to ensure that support is available to her.
Thanks,
The GDS Team
Comment by Michael John posted on
Oh thank you so much for your prompt reply. I feel much better now.
Comment by Kalam Richards posted on
Hi, I’ve received a text from +43 4586 about a tax rebate, however I never made an application. When I click on the link it’s takes me to a gov.uk page where I have to fill out an application. Is this a scam?
Comment by The GDS Team posted on
Hi Kalam,
You’ll never get an email, text message or phone call from HM Revenue and Customs (HMRC) which:
- tells you about a tax rebate or penalty
- asks for your personal or payment information
Check HMRC’s guidance on recognising scams if you’re not sure. You can find more information here.
Thanks,
The GDS Team
Comment by Craig posted on
I would like some advice please regarding going to work during this covid 19 pandemic. I have now self isolated for 14 days as I am an asthma sufferer, and may have come into contact with someone infected with the virus. I am now due to go back to work this week and I am worried about the risks. I am employed by an online retailer who employ 40 staff and although my work can be done online, the company does not have the equipment or resources to allow me to work from home. My employer sells mainly electronic equipment through eBay and Amazon, and sells 100’s of items a day. My question is should they be trading as they sell. Non- essential goods?
Comment by The GDS Team posted on
Hi Craig,
You can find what help/advice you can get if you’re affected by coronavirus (COVID-19).
Thanks,
The GDS Team
Comment by Matthew Steeples posted on
Great to see this level of detail, while at the same time not requiring a degree in computing to understand it!
Comment by Michael v. John posted on
Living abroad and knowing that my 92 year old mum is on her own struggling
with getting fresh fruit and vegetables from a corner shop, I would like to know, if the government is thinking of arranging help for people as vulnerable as her.
Comment by The GDS Team posted on
Hi Michael,
Has your mother registered to get support as a clinically extremely vulnerable person?
Thanks,
The GDS Team